gzip at about the same speed.
The following table gives an overview of the compression rates achieved
with gzip and XMill for six data sources.
A description of each
data source is available by clicking on the source name.
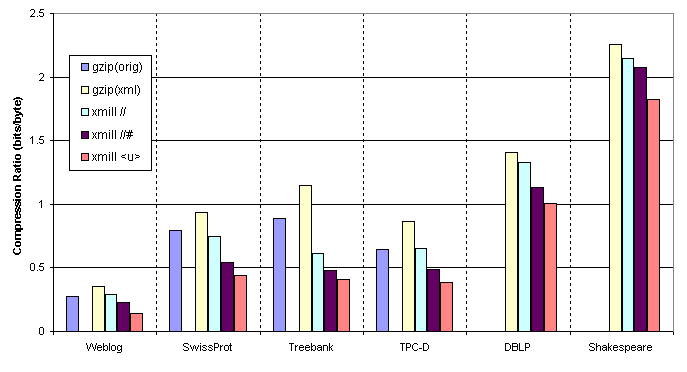
| Size(orig) | Size(XML) | gzip(orig) | gzip(xml) | xmill // | xmill //# | xmill <u> | |
| Weblog | 57.7 MB | 172 MB | 5.92 MB | 7.59 MB | 6.27 MB | 4.85 MB | 3.02 MB |
| SwissProt | 98.5 MB | 158 MB | 15.7 MB | 18.4 MB | 14.8 MB | 10.7 MB | 8.73 MB |
| Treebank | 39.6 MB | 53.8 MB | 5.97 MB | 7.71 MB | 4.12 MB | 3.24 MB | 2.73 MB |
| TPC-D | 34.6 MB | 119 MB | 9.63 MB | 12.9 MB | 9.71 MB | 7.22 MB | 5.76 MB |
| DBLP | 47.2 MB | 8.29 MB | 7.82 MB | 6.66 MB | 5.93 MB | ||
| Shakespeare | 7.3 MB | 2.06 MB | 1.96 MB | 1.89 MB | 1.66 MB |
The first four data sources have been converted from domain-specific data formats. For example, the format used for weblog data is based on the Apache Log Format. The last two data sources, DBLP and Shakespeare, are already XML formatted.
One can observe that the size of the XML files increases substantially over
the original file formats. Furthermore, the gzip-compressed
original file (gzip(orig)) is smaller than the gzip-compressed
XML file (gzip(XML)).
We applied three types of XMill compressions:
xmill //, xmill //#, xmill <u>.
The first compression method, xmill //, does not group the data elements
at all. Hence, the results are similar to the result obtained using gzip.
The second method, xmill //#, groups the text items depending
on their parent element tag in the XML file. As a consequence, the compression
rate increases. Until now, no user compression has been applied. The last method,
xmill <u>, performs user compression based on pre-specified
path expressions that provide information about domain-specific semantics and
syntax of text items. The last method provides the best compression.
The following diagram illustrates the compression rate (bits/bytes) with respect
to the original XML file. A compression rate of 2 bits/bytes means that the
compressed file size is 25% of the uncompressed XML file size. Note that
the last two data sources are already provided in XML. Therefore, gzip
is only applied to the XML file and no gzip (orig) result is given..
Our goal is to classify XMill in this context and to compare it with existing
compressors with respect to compression rate and compression time.
The efficiency of XMill is largely dependent on the underlying compressor.
In its standard configuration, XMill is equipped with gzip
To obtain a more complete picture about the performance of XMill, we tested
a second version of XMill based on bzip, a compressor that achieves
typically better compression results, but at a significantly slower speed.
The following diagram shows the results in time and space of applying several
existing compressors and XMill to the XML data sources described above.
The (logarithmic) Y-axis
shows the relative compression time with respect to the compression time
of gzip. The X-axis shows the relative compression size with respect
to gzip In other words, a point (X=0.5,Y=3) means that the compressor
compresses the file twice as good as gzip, but is three times as slow.
All compressors are applied to all six data sources. We encircle the data points obtained for the first four data sources (Weblog, SwissProt, Treebank, TPC-D), since we believe that they represent an important class of XML documents where compression is particularly useful.
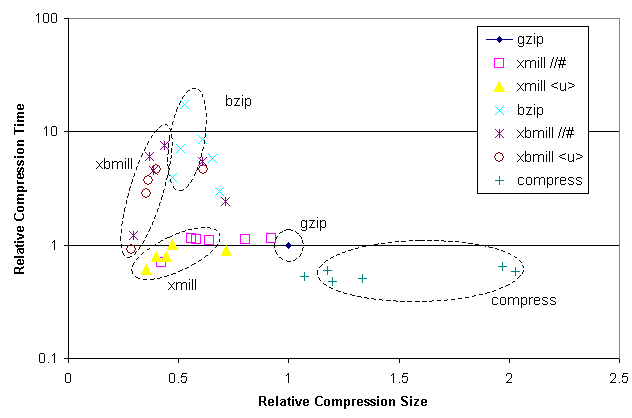
One can observe that both, XMill with gzip and XMill with bzip
perform significantly better than comparable conventional compressors.
Even though the UNIX compress is slightly faster than XMill,
its compression rate is far worse. On the other hand, XMill beats all
conventional compressors in terms of compression rate.
XMill with gzip achieves similar compression rates as bzip,
but as a substantially better speed (about 10 times faster!).
One interesting observation is that XMill with user compression
(i.e. XMill <u>) is always better
(in space and time!) than the corresponding XMill with default
compression (i.e. XMill //#).
This somewhat surprising result is due to the fact that user compressors
pre-compress the data such that the following compression by gzip
and bzip is performed on a much smaller data size.
Copyright © 2004 Hartmut Liefke